Recognizing Surgical Actions and Anatomical Structures for
Gynecological Surgeries with deep learning
Endoscopic videos often show a surgery lasting for hours of routine work. In many cases, surgeons only need to see short video segments of interest to assess a case. However, manually searching and annotating relevant scenes within a large medical multimedia database is a time-consuming task and tedious task. Thus, we aim to support surgeons in this task by providing tools to (semi-) automatically annotate surgery videos to enable fast retrieval of relevant scenes.
The field of computer vision has recently made significant advances using deep learning mechanisms, such as Convolutional Neural Networks (CNN) for image analysis [1]. We adopt this approach for the aforementioned use case of shot detection in endoscopic videos. In particular, we use a dataset containing gynaecological surgeries to train predefined CNN architectures to classify video frames into different semantic concepts of surgical actions and anatomical structures. We also evaluate how the trained CNN architectures perform compared to off-the-shelf CNN features [2] with an SVM classifier.
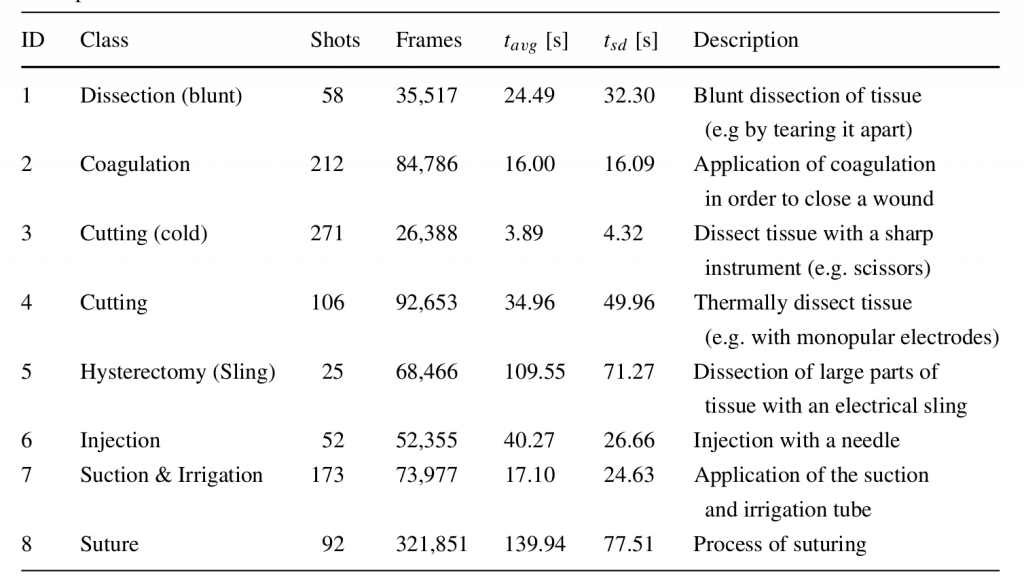
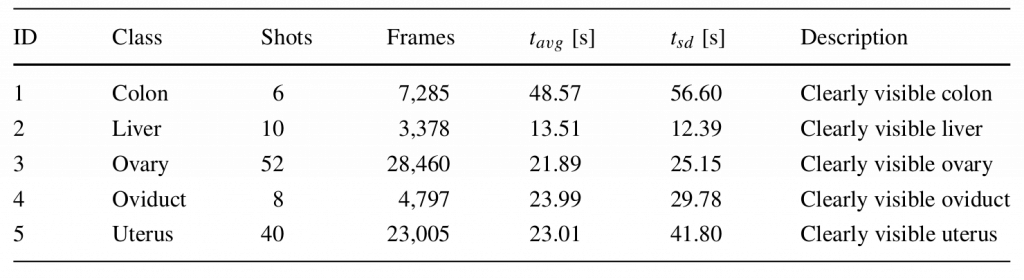
Together with medical experts from the regional hospital Villach (LKH Villach, Austria), we manually annotated hours of raw endoscopic gynecologic surgery [3]. The videos show endometriosis treatment and myoma resection of over 100 patients. Based on a discussion with the medical experts, we identified two main semantic aspects for individual scenes: action and anatomy. Action denotes video scenes that feature significant interaction with the patient’s tissue and organs, using different instruments. These scenes represent the main physical work for the surgeon and are valuable for documentation or teaching certain operation techniques. In total we identified eight sub-classes for actions (e.g., suture, cutting, injection). The anatomy class denotes scenes which feature little or almost no surgical actions apart from moving tissue and organs. The main purpose of such scenes is documentation, in particular the assessment of pathologies on specific organs and their treatment. The identified anatomy sub-classes in the context of endometriosis treatment and myoma resection are uterus, ovaries, oviduct, liver and colon. The cleaned ground truth dataset comprises nine hours of annotated video material from 111 different recordings.
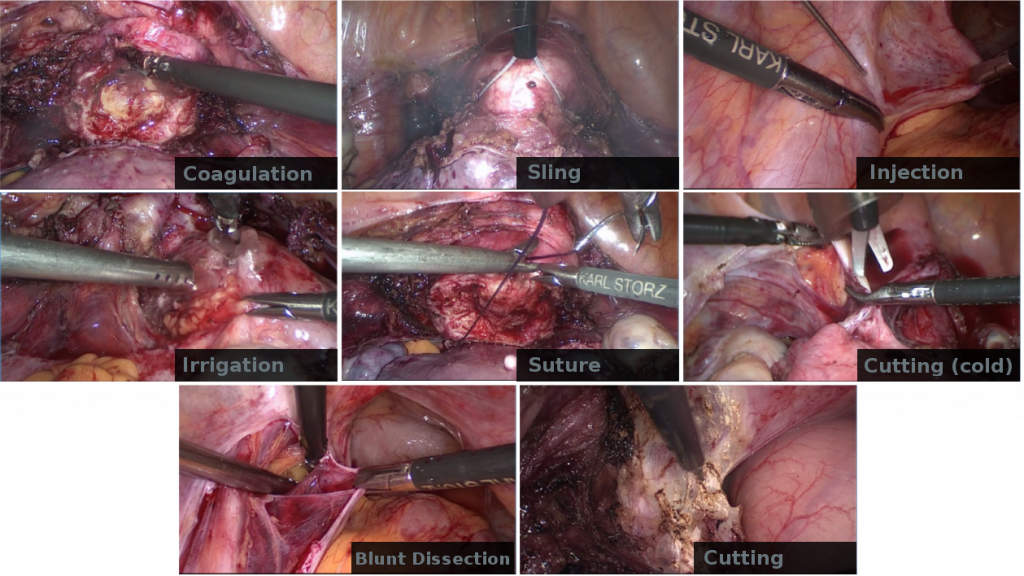
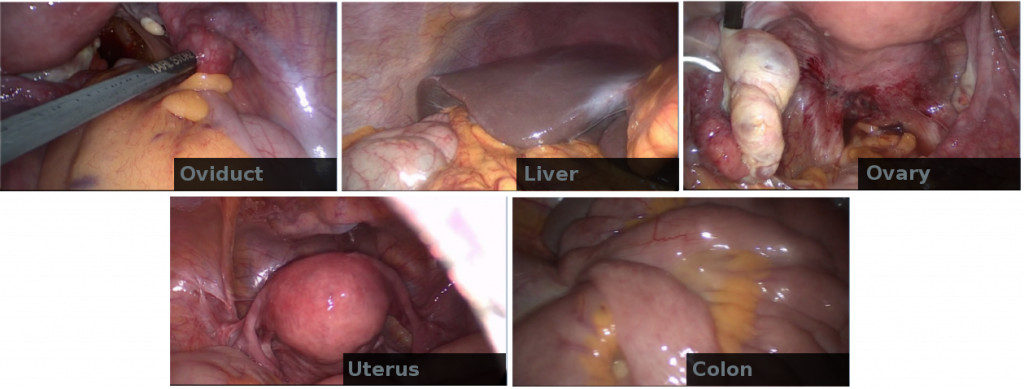
We use the well-known CNN architectures AlexNet [1] and GoogLeNet [4] and train these architectures for both, surgical actions and anatomy, from scratch (with 10% of the images from the dataset). We change the output layer, which is task specific, to contain five and eight output neurons, for anatomy and action classification, respectively. Apart from that, the network structure is not altered. Furthermore, we extract high-level features from the last three layers of AlexNet (i.e., fc6, fc7 and class) with weights from a pre-trained model from the Caffe model zoo and feed them into an SVM classifier. This allows us to investigate how end-to-end trained CNN with a problem-specific classification output layer perform against off-the-shelf CNN features, which have been trained for general purpose image classification.
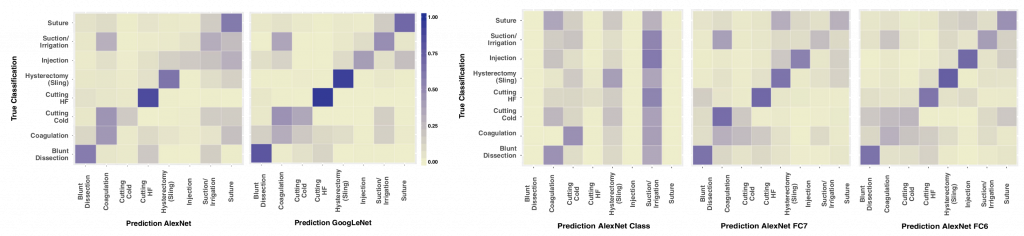
In general, we observe that the GoogLeNet architecture is superior to the AlexNet architecture and SVM Classifiers. On average, GoogLeNet achieves the best results for surgical action classification in terms of Recall (0.62) , Precision (0.59) and f-value (0.85)[5]. However, there are classes where other approaches work better. For example, AlexNet is better at the classification of Coagulation and the SVM approach using layer fc6 is better at classes Injection and Suction & Irrigation. The latter two classes are special, as they feature most reflections. We think that features from AlexNet, trained on the ILSVRC dataset, better map reflections than the models trained on a medical database, where reflections occur constantly. These results also indicate that improvements of CNN methods in the general domain of image classification also lead to improvements in the specialized domain of laparoscopic surgery image classification. For anatomical structure classification, GoogLeNet also dominates the average performance in terms of Recall (0.78), Precision (0.78) and f-value (0.78)[5].
We use confusion matrices to show the class specific classification of the abovementioned classification approaches. Columns denote the predicted class while rows indicate the true class. Cell shades illustrate prediction percentage relative to the number of examples for a class. It can be seen that CNN and SVM action models perform poorest in the classes Coagulation, Cutting Cold and Suction& Irrigation. We think this originates from the fact that the single-frame CNN models have limited means to model the way the instruments are used. For CNN and SVM anatomy models, there is a bias to confuse the classes Ovaries, Uterus and Oviduct. We think the reason is that these organs are spatially very near and hence parts of two or more organs may be seen within the same image which leads to misclassifications. Comparing surgical action to anatomical structure classification performance, it is obvious that anatomical structures perform much better in overall performance. We think this originates in the very complex nature of surgical action scenes compared to more static scenes featuring anatomical structures and the fact that all approaches ignore the temporal dimension.

Despite the fact that this domain is pretty narrow, there is plenty of future work to do. We think a per-pixel classification approach for anatomical structures could yield more accurate results for structures which are spatially near each other. More examples for future work include the evaluation of more sophisticated approaches for video classification, such as frame fusion models or LSTM-based models. Also, the question of whether we can surpass human performance by adding more network depth remains open. However, we think that classification of surgical actions provides the most benefit for surgeons and therefore focus on the following point. We assume that the capabilities of the used single-frame CNN models AlexNet and GoogLeNet are not fully utilized. Hence, we aim at an improvement of surgical action classification by using early fusion of raw image data with multiple (domain-specific) modalities of which at least one represents a temporal dimension, such as motion vectors.
References
- A. Krizhevsky, I. Sutskever, G.E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,“Advances in Neural Information Processing Systems (NIPS), vol. 25, 2012, pp. 1106–1114.
- A. S. Razavian, H. Azizpour, J. Sullivan and S. Carlsson, “CNN Features Off-the-Shelf: An Astounding Baseline for Recognition,” IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2014, pp. 512-519.
- S. Petscharnig, K. Schoeffmann, “Deep learning for shot classification in gynecologic surgery videos,” Proc. of Int. Conf. on Multimedia Modelling, LNCS 10132., 2017. pp. 702-713.
- C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, A. Rabinovich, “Going deeper with convolutions,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, 2015. pp. 1-9.
- S. Petscharnig, K. Schoeffmann, “Learning laparoscopic video shot classification for gynecological surgery,” Multimedia Tools and Applications, April 2017. pp. 1-19.