Analysis of Ophthalmic Videos
Cataract is known as clouding of the eye’s lens, a defect that often occurs in the course of aging. This condition can be treated with a surgical procedure where the natural lens is removed and an artificial lens is implanted. The surgeon looks at the patient’s eye through an optical microscope. These surgical microscopes usually have an additional optical system with a mounted camera to acquire a video signal. This video stream is displayed on a monitor and can also be recorded on a digital medium. Cataract surgery is by far the most frequently performed surgical procedure in the medical specialty of ophthalmology. Thus, it follows broadly accepted rules and can be called a quasi-standardized procedure.
Cataract surgery is a very interesting domain for medical multimedia research, since this procedure is very common, a video signal is available without any additional effort and the procedure is well standardized. In particular, one of the fundamental problems is the automatic understanding of the surgical workflow and the temporal segmentation of this workflow into surgical phases. Such an automatic segmentation could greatly improve documentation and also support surgeons browsing and retrieving relevant scenes from large medical multimedia databases. Additionally, real-time processing methods could support surgeons during the procedure in order to recognize or prevent adverse events, by detecting deviations from the surgical process model.
We address the problem of segmenting a cataract surgery video into distinct surgical phases with a frame-based classification approach [1]. Each video frame is classified separately as belonging to a particular phase. We use Convolutional Neural Networks (CNN) [2] as underlying classification framework. CNN have proven to perform very well for general classification tasks but also have achieved good results in shot classification for other types of surgery videos [3]. In particular, we use the GoogLeNet architecture [4] and train it from scratch. Apart from changing the output layer to contain the number of different phases, the architecture remains unchanged. Since there are no public datasets of cataract surgery videos are available, we prepared a dataset with ground-truth annotations to evaluate our proposed approach and provide it for public use by the scientific community . To improve the quality of the dataset, we applied two pre-processing methods and also evaluate how these methods affect the classification performance of our CNN approach.
A usual cataract surgery has a duration of five to ten minutes and can be divided in eleven phases. The durations of the different phases are not equally distri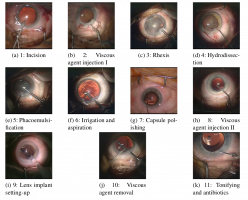 buted. The longest phase (phase 5) takes approximately one third of the surgery’s duration, whereas the phases 2 and 8 represent the shortest phases. Since the phases 2 and 8 are identical with respect to both visual appearance and semantics (viscous agent injection), they are treated as a single class for classification purposes. Thus, our classification is based on ten phases. Typically, the pupil is wide opened and the iris is very small during the entire procedure. The position and color of the lens change, which may negatively affect analysis methods. In a cataract surgery only a small set of instruments is used and most of the instruments are used only within a specific phase. However, instruments may appear from the left, the right or from both sides.
buted. The longest phase (phase 5) takes approximately one third of the surgery’s duration, whereas the phases 2 and 8 represent the shortest phases. Since the phases 2 and 8 are identical with respect to both visual appearance and semantics (viscous agent injection), they are treated as a single class for classification purposes. Thus, our classification is based on ten phases. Typically, the pupil is wide opened and the iris is very small during the entire procedure. The position and color of the lens change, which may negatively affect analysis methods. In a cataract surgery only a small set of instruments is used and most of the instruments are used only within a specific phase. However, instruments may appear from the left, the right or from both sides.
Medical experts from Klagenfurt hospital provided us a dataset consisting of 21 video recordings of cataract surgeries which have been performed by four different surgeons. Since the dataset is rather small (it contains around 212000 frames) and unbalanced (i.e., phase 5 and 6 contain nearly half of all the frames), we perform some pre-processing to enhance the quality of the dataset. First, we manually remove frames that belong to a certain phase but do not show any instruments (so called idle periods). Second, we balance the dataset so that for each phase the same amount of frames is used to train the CNN. As described before, cataract surgery follows a quasi-standardized routine. Hence, we expect that temporal information is a useful information which can improve classification results. To exploit temporal information, we added a relative timestamp (i.e., frame number/total number of frames) to each frame.
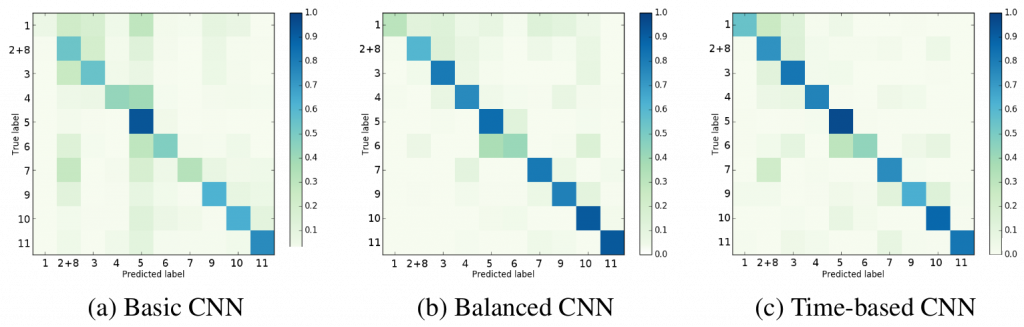
Our evaluations show that a pre-processing of the dataset is needed. The CNN that has been trained with the cleaned and balanced dataset outperforms the CNN that relied on the original dataset. In particular, the balanced CNN achieved an average precision of 0.69, whereas the basic CNN only achieved a precision of 0.65. Similarly, the balanced CNN achieved a higher recall (0.67 vs. 053) and a better F1-score (0.68 vs. 0.59). Taking temporal information into account further improves the classification results. The time-based CNN achieves a precision of 0.77, a recall of 0.74 and a F1-score of 0.75.
The evaluation showed that a CNN can be used to detect phases in a cataract surgery video. Especially, the use of a cleaned, balanced dataset and temporal information can improve classification performance. For future work we want to extend the CNN model to classify several optional phases as well as to detect complications. The development of such a neural network would enable further tools like automatic keyframe detection for documentation, video summarization or operation planning.
References
- MJ. Primus, D. Putzgruber-Adamitsch, M. Taschwer, B. Munzer, Y. El-Shabrawi, L. Boszormenyi, K. schoffmann, “Frame-based Classification of Operation Phases in Cataract Surgery Videos, ” submitted to Int. Conf on MultiMedia Modeling (MMM), 2018.
- A. Krizhevsky, I. Sutskever, G.E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” Advances in Neural Information Processing Systems (NIPS), vol. 25, 2012, pp. 1106–1114.
- S. Petscharnig, K. Schoeffmann, “Learning laparoscopic video shot classification for gynecological surgery,” Multimedia Tools and Applications, April 2017. pp. 1-19.
- C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, A. Rabinovich, “Going deeper with convolutions,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, 2015. pp. 1-9.